

시작하며,
첫 글은 2024년 7월, 핀포인트 리서치를 위해 작성한 리서치 자료로 찾아뵙습니다. 이 글은 초고 작성 직후 Adept AI의 리버스 어크하이어(reverse acqui-hire) 소식으로, 핀포인트에서 발행하지 않고 개인적으로 간직하고 있던 글입니다.
지금은 비록 오래되어 가치를 많이 잃었지만, 열심히 고민하며 쓴 글인 만큼, 서브스택의 첫 글로 올리고 싶었습니다.
앞으로 좋은 글을 많이 들고 오겠습니다. 잘 지켜봐 주세요. 감사합니다!
(구독 부탁드립니다!)
thesis
인간이 지닌 고유한 지능은 인간을 다른 대부분의 동물과 구분되게 하는 절대적 능력이자 인간 문명의 발전을 가능하게 한 핵심 동력이다. 사고한다는 추상적인 능력이 인간의 육체 능력과 유기적으로 연결되어, 인류는 지구의 다른 어떤 종(species)도 이뤄내지 못한 지배력을 강구해낼 수 있었다.
이런 지배력의 유지에는 생산성 증대가 핵심이었다.
농업 도입에 따라 인류가 수렵채집 중심의 사회에서 생산 중심의 경제로 이동한 이후로, 생존에 있어서 “자원을 어떻게 효율적으로 생산할 것인가?”에 대한 문제가 중요한 문제가 되었다. 가령 많은 양의 식량을 생산해야 더 큰 인구를 부양할 수 있다는 것처럼 말이다. 이런 양과 생산성에 대한 집착은 계속 이어져 왔고, 인류는 끊임없이 생산성 증대를 위해 연구하게 된다. 그런 발전이 집약적으로 나타난 시기가 산업 혁명이다.
산업 혁명은 곧 생산성의 혁명이었다. 세 차례의 산업혁명에서, 인류는 증기 기관의 도입, 광범위한 과학 기술의 도입, 그리고 디지털 장비의 도입으로 엄청난 생산성 발전을 이루어냈다. 이렇게 각 단계에서 혁신적인 기술의 도입으로 인간이 더 많은 일을 기계에게 위탁할 수 있게 되면서, 인류는 점차 고수준(high-level)의 과업에 집중하는 형태로 삶의 양식을 바꾸게 되었다.
한편, 인간의 지능을 모방하는 AI 기술이 이 세 차례의 혁명을 이어 네 번째 산업혁명을 이끌어갈 것이라고 보는 시각이 많다. 기존의 기계는 설계된 대로, 인간이 이해할 수 있는 수준의 흐름도를 따라가도록 작동한다면, 인공지능 기술은 엄청난 컴퓨팅 능력을 바탕으로 인간조차 읽을 수 없는 세상의 패턴을 캐치하고 분석하여, 사람이 이해할 수 있는 형태로 표현할 수 있기 때문이다.
하지만 이런 엄청난 능력에도 불구하고, 아직 AI가 직접 day-to-day life에서 사람들에게 영향을 주고 있지는 않다. 예를 들어 ChatGPT가 지식 노동자에게 조언을 줄 수는 있지만, 많은 경우 그들을 대신해서 일을 해 줄 수는 없지 않은가?
이런 강력한 AI 기술의 힘과 실제 지식 노동자들이 맞이하고 있는 문제 사이의 갭을 줄여주고 싶은 회사 Adept가 있다. Adept의 궁극적 목표는 안전한 일반 인공지능(useful general intelligence)을 만드는 것이지만, 그 과정에서 실제로 인간이 일자리에서 활용할 수 있는 product를 만드는 단계가 반드시 동반되어야 한다고 믿는다. 그들이 꿈꾸는 product는 “컴퓨터 수석 비서관”과 같은데, 기본적으로 언어로 된 명령을 이해해 컴퓨터에서 수행해낼 수 있고, 제시된 명령이 아니라 필요해 보이는 일도 스스로 발굴해낼 수 있는, 컴퓨터 상의 프로그램이자, 지식 노동자를 도와주는 ”AI teammate”이다. 이런 teammate는 더 나아가 여러 가지 반복적인 일의 자동화를 가능케 하여, 사용자가 불필요한 업무에 쏟는 시간을 줄이고 핵심적인 일에만 집중할 수 있게 도움을 주어, 새로운 생산성 혁명의 시작을 열 것이다.
동사는 비록 2022년 초에 창립되어 아직 태동기에 있지만, 이런 vision을 가지고 AI 투자의 혹한기 속에서 Series B 투자를 성공적으로 유치하며 유니콘이 되었다. 이런 열기 속에서 투자자들은 어떤 가치를 보았던 것인지, 그리고 동사는 어떤 세상을 꿈꾸는지를 살펴보며, 동사에 대한 분석을 시작하자.
founding story
Adept의 창업자인 David Luan은 잘 숙련된 AI 기술 전문가이자, AI Safety에 대한 전문가이다.
Luan은 12살이 채 되지 않은 나이에 아버지를 따라 Worcester State University에서 심야 수업을 들으면서 CS 과정을 수료하고, 이후 Yale 학부에 진학하여 응용 수학 및 정치학 학위를 받은, 어릴 때부터 두각을 드러낸 천재였다. ML이 지금만큼 큰 붐을 불러일으키기 한참 이전인 2009년 즈음부터, Luan은 iRobot Research, Microsoft과 같은 당시의 핵심 산업체들에서 ML 기술을 익히게 되고, 그 경험을 활용하여 Dextro라는 영상 인식 스타트업을 창업한다. 그리고 Luan은 그곳에서 최초의 실시간 사진 인식, 영상 인식 기술을 개발해 $7.5M의 가격으로 테이저, 바디캠 등을 제작하는 기업인 Axon에 회사를 매각한다.
그 후 Luan은 당시 주목받던 OpenAI에 Director of Engineering으로 합류하게 되고, 그곳에서 GPT-2, GPT-3, CLIP, DALL-E 등의 핵심 프로젝트에 참여하며 거대 모델 개발에 대한 모든 것을 배운다. 이후 Google Research로 옮겨 Large model과 관련된 사업부의 총괄 테크 lead 포지션을 맡는다.
“My main focus is research, but most of my career has revolved around near- and long-term impacts of AI on society. I’m interested in how the dynamics of AI development can shape outcomes for people, and I try to spend as much time as possible with ethics, safety, and policy researchers.”
/ davidluan.com
본인도 이야기하듯, Luan의 커리어에서 단순히 딥러닝 리서치만 해온 것이 아니라, AI Ethics, safety에 관련된 일을 계속 해 왔다는 점이 특별하다.
Axon에서는 사업부에 윤리적 사안에 대해 조언하는 독립 기구(Axon AI Ethics Board)를 창립 및 운영하였고, Apollo Global Management Inc.의 Impact Advisory Committee(사회적 impact 창출을 위한 투자 자문위원회)의 일원으로 참여하면서, 일선 현장에서 AI의 안전한 사용에 대해 오랜 시간 동안 고민하며 경험을 쌓아 나갔다.
이렇게 AI의 안전한 사용에 관한 경험과 전문 researcher로의 경험에서, 그는 안전한 일반지능을 만들기 위해서는 사람 중심의(human-centered) 접근이 핵심적이라는 믿음을 갖게 되었고, 이 인사이트가 동사의 창업의 핵심 정신이 된다.
“… [this product vision] excites us not only because of how immediately useful it could be to everyone who works in front of a computer, but because we believe this is actually the most practical and safest path to general intelligence”
/ adept.ai
그렇게 Luan은 Google Brain에서 함께 근무하던 Research Scientist이자 Google Brain의 전설적인 “Attention Is All You Need” 논문의 공동저자로 이름을 알린 Niki Parmar, Ashish Vaswani와 함께 2022년 1월, 컴퓨터를 활용할 수 있는 안전한 일반지능의 개발을 꿈꾸며, Adept를 창업한다.
9명의 팀으로 시작한 Adept는 2년이 막 넘은 지금, 초기 서비스 개발과 기술력 혁신에 집중하고 있고, 엔터프라이즈 고객 위주로 사업을 확대해 나가며 Series B funding을 마친 상태이다.
본격적으로 분석을 시작하기 전, 인공지능 기술에 대한 몇 가지 용어를 정리하고 넘어가자. 쉬운 이해를 위해 기술적인 디테일보다는 큰 개념 위주로 정리하였다.
fine-tuning: 이미 만들어진 모델을 특수한 목적에 맞게 더 훈련시키는 과정이다.
Foundation model: 일반적으로 광범위한 데이터로 학습된 모델은 fine-tuning을 통해 다른 task들에 특화된 모델로 만들 수 있는데, 이런 모델을 foundation model이라고 한다. GPT 모델들이 대표적이다.
Scaling law: 더 많은 데이터로 더 큰 모델을 훈련시킬수록 (scale을 키울수록) 그것에 비례해서 모델의 지능 수준이 높아진다는 관습적 이론이다. 관심 있는 독자는 여기(https://gwern.net/scaling-hypothesis#flexing-gpt)에서 구체적으로 더 읽어볼 수 있다.
Transformer: 2017년 제안된 AI 모델의 구조로, 이 구조를 변형하고 확장해서 많은 거대 AI 모델이 만들어졌다.
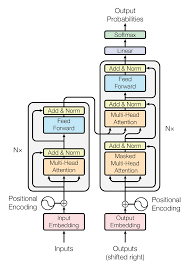
multimodal model: 여러 개의 형식(text, image 등)을 이해할 수 있는 모델이다.
AI agent: 실제로 세상에 행동을 취할 수 있는, “agent” 같은 인공지능 프로그램을 의미한다.
product
동사가 설립 2년이 갓 된 초기의 스타트업이다 보니 알려진 바가 많이 없어, 동사가 그리는 야심찬 청사진과 구체적인 product vision이 아무래도 동사를 평가할 때 가장 인상적인 부분이다.
많은 사람들이 AI 기술이 인류에게 혁신을 가져다 준다는 명제에는 동의하지만, 그에 반해 아직 구체적인 청사진을 그려내는 기업은 많지 않다. 그런 부분에서, 동사의 product vision을 분석함으로써 AI 혁명의 최전선을 간접적으로나마 바라볼 수 있고, 빠르게 판도가 바뀌는 AI 시장에서 동사의 경쟁력을 가늠할 수 있는 가장 중요한 부분이기에, 많은 분량을 할애해 동사가 어떤 꿈을 갖고 있고, 어떤 과정을 밟고 있는지 분석하고자 한다.
overview
동사는 컴퓨터 앞에서 일하는 지식 노동자들이 실질적으로는 반복적인 업무에 시달린다는 문제를 발견하고, 주목하게 된다. 특히 이런 업무는 서로 다른 소프트웨어에 의존하는 경우가 많은데(지식 노동자는 평균적으로 18개의 서로 다른 소프트웨어를 사용한다고 한다), 이런 특성으로 인해 같은 업무를 반복해서 수행하면서 지식 노동자들은 시간과 노동력을 낭비하고 있는 것이다.
이런 문제를 해결하기 위해 이미 고안된 RPA 툴들은 비교적 비용은 적지만 너무 초보적인 수준이라 실제 workplace에서 일어나는 일들에 효과적으로 적용하기 힘들다. 반대로 코딩과 같이 강력한 해결책들도 있지만, 1) 잔업무를 코딩으로 해결하기에는 시간과 비용이 많이 들고, 2) 코딩할 수 있는 인력(능력)이 필요하기에 필요한 코스트가 지나치게 높다. 즉 강력한 기능성과 cost 사이의 tradeoff가 있는 상황이다.
동사는 이런 문제를 AI 기술로 메워내고자 결심한다. AI 기술을 활용해서 개인이 자동화할 수 있는 일의 범위를 늘려서, 지식 노동자들에게 낮은 비용으로 업무를 자동화시킬 수 있는 기회를 제공하려고 한다.
이 방면에서의 혁신은 자연어 처리 기능에 있다. 기존에는 “이 엑셀 시트의 2번째 셀을 눌러서, 이 값을 입력하고, …”와 같이 순서도를 직접 만들어야만 RPA를 사용할 수 있었는데, 동사의 제품은 “엑셀에 있는 정보를 웹사이트의 검색 부분에 넣어줘.” 같은 언어 기반 명령을 이해하고, 스스로 해결 방법을 구상해서, 실행 및 자동화까지 이뤄낼 수 있는 기술이다.
A synthesizer lets a musician play sounds of every instrument without having to learn how to play every instrument. We want to build the same thing for computing.
/ “Introducing Adept”, adept.ai
궁극적으로는 더 나아가서, 단순히 주어진 문제를 해결하는 게 아니라, 지능을 가져 문제를 스스로 발굴하고, 조율하는 등 사용자에게 적극적인 도움을 줄 수 있는 서비스를 제공하고자 한다. 영화 아이언맨에서 아이언맨의 비서 자비스(J.A.R.V.I.S) 같은 존재를 말이다.
/ iron man의 J.A.R.V.I.S. (Just A Rather Very Intelligent System).
이런 목표를 가진 동사의 중간 milestone은 크게 두 단계로 나눌 수 있겠다.
첫째는 컴퓨터에 자연어(natural language) interface를 만들어서, 자연어로 된 명령을 이해하고 그 명령을 실행시킬 수 있는 reactive한 성격의 interface를 만드는 것이다.
둘째는 이런 자연어 인터페이스가 장착된 컴퓨터에 지능을 불어넣는 일이다. 컴퓨터가 사용자의 활동을 모니터하면서, 여러 정보를 수집하고, 이를 바탕으로 사용자에게 proactive한 도움을 주는 것이다.
이제 각각에 대해 동사가 어떤 일을 해오고 있는지 더 자세히 알아보자.
Natural Language Interface
먼저 GUI(Graphical User Interface)를 대체할 자연어 interface에 대해 알아보자.
키보드와 마우스를 조작해서, 컴퓨터에 입력을 전달하고, 컴퓨터의 출력을 모니터로 관찰하고, 그 결과를 바탕으로 다음에 어떤 조작을 할 것인지를 결정하는 현재의 GUI가 있다면, 동사의 제품을 이용해서는 컴퓨터를 활용하는 사용자들은 키보드, 마우스, 모니터와 같은 입출력 장치 대신 자연어로 컴퓨터에게 명령하게 되는 것이다. 컴퓨터는 이런 자연어 명령을 완벽하게 이해하고, 어떤 과정으로 그 목적을 달성할지 스스로 설계한다(workflow를 만든다). 그리고 컴퓨터 화면 UI를 통해 직접 클릭이나 가상 키보드를 조작하여, 설계한 단계를 순차적으로 실행한다(workflow를 실행한다).
Workflow generation + execution
그럼 동사는 자연어 명령에서 workflow를 만드는 일, 그리고 만든 workflow를 실행하는 일을 어떻게 해내고 있을까? 지금까지 알려진 정보들을 정리해 보자.
먼저 동사의 본질은, product을 만드는 기업이라기보다는, AI Lab으로, 스스로를 AI 리서치 랩으로 정의할 만큼 원천 기술의 개발이 동사에게 중요한 부분이다. 여기서 동사가 집중적으로 개발하는 모델은 크게 두 종류인데,
세상과 상호작용하는 모델: 컴퓨터 내에서 직접 action들을 제작하고, 실행 가능한 모델 (ACT-1)과
세상을 이해하는 모델: scaling을 통해 성능 향상이 가능한 multimodal foundation model (Fuyu-8B, Fuyu-Heavy, Persimmon-8B)
이 있다. (구체적으로 이런 모델들이 어떠한 방식으로 결합되어 동사의 product를 구성하는지는 알려지지 않았지만, 아마 2)의 모델이 “세상을 이해"하는 역할을 하면서 1)의 모델 안에 내장되어 실행되는 형태가 아닐까 예상해 본다.)
ACT-1 (Action Transformer-1): Transformer for actions
2022년 9월에 공개된 ACT-1은 동사의 핵심 기술인 “컴퓨터 domain을 이해한다”는 기능을 충실하게 이행하는 모델이자 동사의 MVP를 구동시키는 Transformer 기반의 모델이다. GPT가 텍스트를 위한 모델이고, DALLㆍE가 이미지를 위한 모델이면, ACT-1은 “컴퓨터 상의 행동(action)”에 대한 모델이라고 생각할 수 있다.
백문이불여일견이라 하니, ACT-1으로 작동하는 아래의 데모 영상을 보자.
아무래도 ACT-1 모델이 실제 컴퓨터와 상호작용하는 기능을 하는 모델이고, 기존에는 비슷한 기능을 하는 모델이 없었기에, 동사의 핵심 moat로 시장 내에서의 동사의 포지션을 지켜주는 모델이다. 동사가 다른 일부 LLM 모델을 오픈소스로 공개한 점에 반해, 공개하지 않은 모델이라는 점을 생각하면 더더욱 그 중요성을 알 수 있다.
아직은 이 demo가 Chrome extension 형태로만 존재하지만, 데스크탑에서 작동하는 버전을 곧 출시할 계획이라고 한다.
Multimodal Models: Fuyu-8B, Fuyu-Heavy
동사 제품에 직접적으로 사용되는 Fuyu 계열의 모델은 multimodal 모델로, 실제로 UI를 이해하고, 자연어를 이해하는 역할을 하는 것으로 보인다. 동사의 전략은 scaling law를 따라서, Fuyu 계열의 모델 크기를 점점 크게 만들면서 더 높은 지식 수준을 갖춘 모델을 만들어 성능의 향상을 가져오고 싶은 것으로 보인다.
지금까지는 초기 모델인 Fuyu-8B와 한 번 scale up된 Fuyu-Heavy 모델만이 공개되었는데, 스펙을 간단히 정리해보자.
Fuyu-8B
Open-source (AI 개발을 도와주는 플랫폼인 HuggingFace에서 이용 가능하다)
Multimodal (가변 크기의 이미지와 글을 모두 처리 가능하다.)
특히 뛰어난 표, 그림 자료 이해력과 UI 이해력이 인상적이다.
Fuyu-Heavy
10-20배 큰 GPT4-V, Gemini Ultra에 이어서 세 번째로 성능이 좋은 모델 (24.1.24 기준)
Multimodal reasoning에 특화되어 있고, 특히 Fuyu-8B처럼 UI 이해에 특화되었다.
동사가 공개한 성능 비교 표는 다음과 같다. 아무래도 Fuyu-heavy의 개발 목적이 UI understanding에 있는 점을 감안하면 industry에서 널리 쓰이는 metric 등이 모델의 성능을 평가하는 데에 완벽하지는 않지만 (+ 성능이 잘 나온 metric만 공개했을 가능성을 고려하면), 동사가 최고(state-of-the-art)에 버금가는 기술력을 가지고 있다는 점은 알 수 있다.
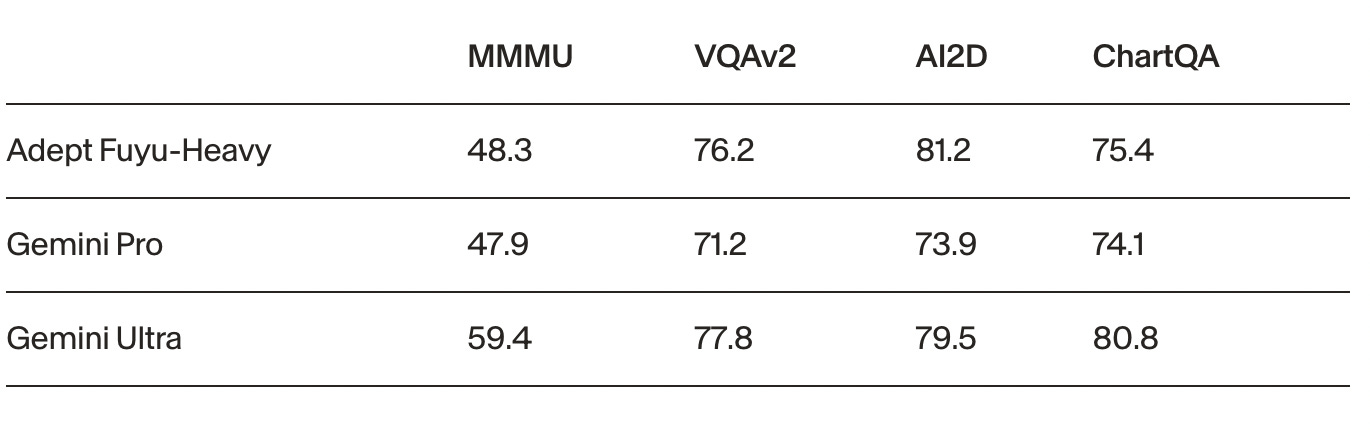
/ Fuyu-Heavy performance (adept.ai)
위 결과들을 종합해 보면, 최소한 동사의 in-house 모델은 AI foundational model을 만드는 OpenAI, Google의 SOTA 모델에 비해 전혀 뒤떨어지지 않는다는 점은 명백해 보인다. 다만 특수한 목적 없이 일반적인 용도로 거대 모델을 개발하는 기존 기업들과 달리, 동사의 Fuyu 계열 모델은 컴퓨터와 상호작용하기 위한 UI 이해 능력까지 가지고 있기 때문에 현재까지는 확실한 기술적 해자가 있고, 이런 모델을 만들어내는 팀이 있다는 사실이 앞으로도 기술 개발 경쟁에서 밀리지 않을 것임을 증명하고 있다.
Adept Experiments
동사는 현재 enterprise 전용 솔루션 개발에 몰두하고 있다고 밝힌 바 있다. Enterprise 내부에서 사용하는 몇 개의 프로그램을 대상으로, 동사가 개발한 기본 모델에 그 프로그램에 따라 특수하게 설계된 fine-tuning 과정을 거쳐, 실제 사용에서는 95% 이상의 엄청난 정확도를 갖고 있는 솔루션을 제공하고 있다고 한다.
이러한 부가적 fine-tuning 과정을 제외한, 조금 더 일반적인 용도로 사용할 수 있지만 상대적으로 부정확한 기본 모델을 2023년 9월, Adept Experiments라는 샌드박스 형태로 공개하였다.
현재의 Adept Experiments의 핵심 기능은 workflow를 직접 만들고 실행시키는 기능을 지원하는데, 다음 기능들이 핵심적이다:
화면에 있는 정보에 대한 질문을 대답하는 기능(ex: 가운데 있는 동물의 종류는? -> “소”),
기술된 특징에 맞는 element를 클릭하는 기능(ex: 사람이 걷는 그림 클릭해줘.),
질문에 따라 답변을 생성하고 그 답변을 UI에 입력하는 기능(ex: 오늘의 날짜를 세 번째 칸에 입력해줘.),
화면에 기술된 특징에 맞는 element가 있는지 판별하는 기능(ex: 초록색 박스가 있어?),
기술된 만큼, 정해진 방향으로 scroll하는 기능(ex: 체크박스가 나올 때까지 스크롤해줘).
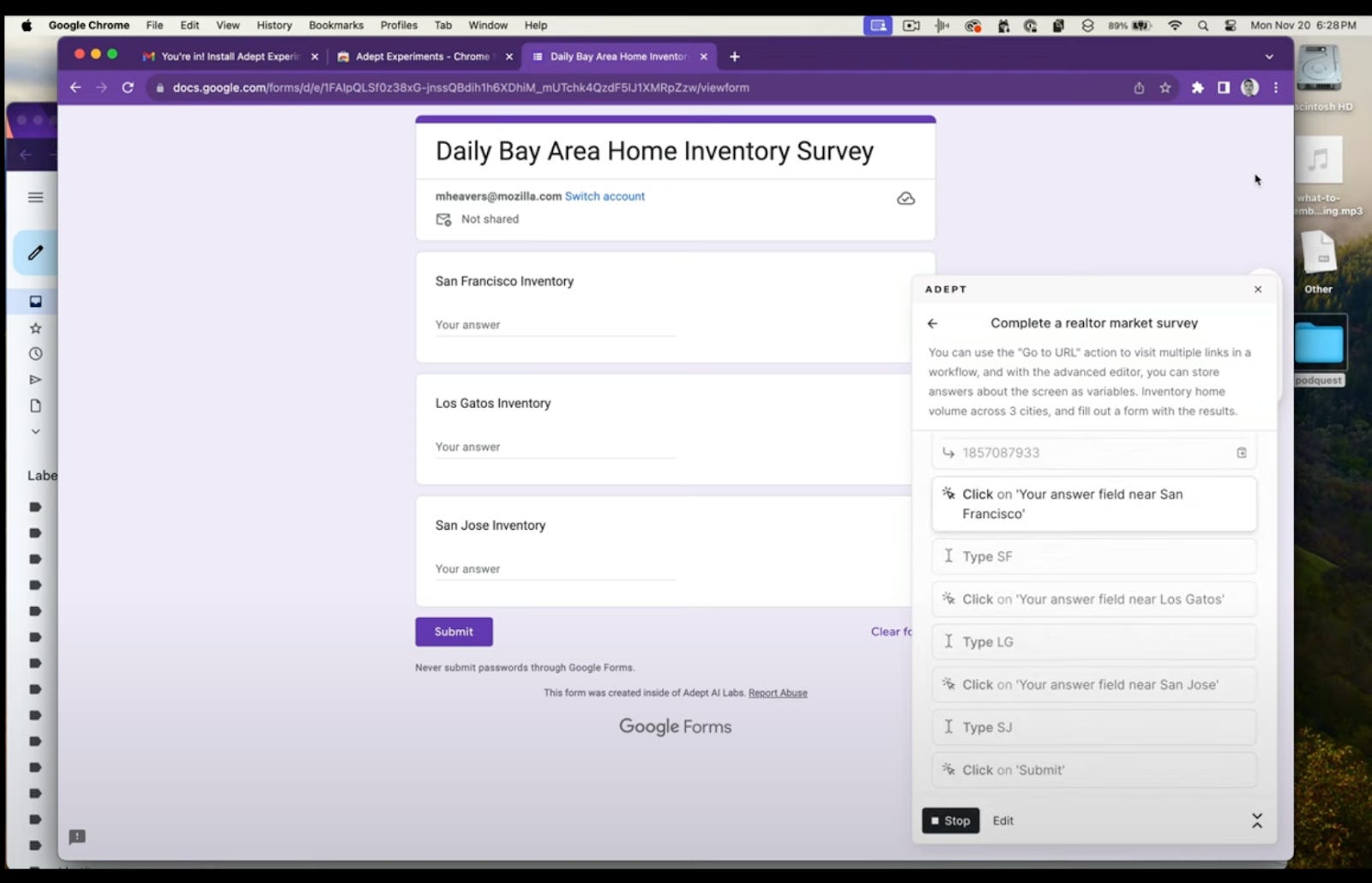
이 기능들을 이용해서 사용자는 직접 workflow를 만들 수 있고, 아니면 text로 된 명령을 입력해서 그 명령을 수행하는 workflow를 생성할 수 있다.
AI teammate
이렇게 동사가 어떻게 workflow 생성 및 실행을 구현하는지 알아보았는데, 동사의 꿈은 이런 자연어 인터페이스로서의 서비스를 넘어선다. 단순히 명령을 처리하는 것이 아니라, 실제로 지능을 갖고 인간과 같이 일하고, 어떤 일이 필요한지 조언해줄 수 있는 동료로서의 서비스, 곧 “안전한 일반지능”이 그 끝이다.
아직 이런 일반지능이 어떠한 형태로 도래할 지는 모르지만, 동사는 이런 general intelligence가 최소한 a) “사람이 컴퓨터를 통해 할 수 있는 모든 일을 대신 수행할 수 있고”, b) “마우스나 키보드가 아닌, 자연어 인터페이스를 가져야” 할 것이라고 설명한다. 동사가 꿈꾸는 일반지능의 시대에서는 인간이 처음 보는 소프트웨어를 사용할 수 있게 되고, 그 과정에서 documentation, 매뉴얼, FAQ 등은 모델을 위한 것으로, 인간이 직접 읽을 필요가 없게 된다.
이런 일반지능에 근접한 단계로 개인 AI 수석비서관이 있다: 컴퓨터 백그라운드에서 사용자가 평소에 사용하는 정보를 수합하고, 그 정보를 바탕으로 “수석비서관”의 기능을 하는 소프트웨어. 가령 따로 캘린더에 일정을 등록하지 않아도, 목격한 정보를 바탕으로 “오늘 할 일 알려줘”와 같은 질문에 응답한다거나 (비서 기능), 이메일 사용 기록을 바탕으로 “기존에 했던 일에 대한 follow-up task”를 제안한다거나 (능동적인 조언), 사용자가 “마켓 리서치를 쓰고 싶은데 어떻게 해야 할까?”라고 물어볼 때 가능한 task의 완수 방법을 제안한다거나 (수동적인 조언) 등을 할 수 있는 서비스이다.
CEO인 David Luan은 개인 수석비서관 수준의 지능은 1-2년 이내에, 보수적으로 잡아도 5년 이내에 개발 가능하다고 예측하는 만큼, 동사가 가져올 새로운 생산성 혁명의 시작이 얼마 남지 않았음을 다시 한번 느낄 수 있다.
market
동사 제품의 사용자는 넓게 보면 컴퓨터를 활용하는 모든 지식 노동자이지만, 현재 동사는 enterprise 고객에 집중해서 맞춤형 솔루션을 제공하려 하고 있다. 이후 AI teammate 역할을 하는 개인용 소프트웨어를 제공해서 더 넓은 전체 지식 노동자 시장을 겨냥할 계획이다.
그러면 이 두 target market 중 enterprise 고객에 집중하는 것이 타당할까? 동사가 각 market에 가져다줄 수 있는 가치 및 시장 크기, 그리고 그에 따른 리스크에 맞춰 생각해보자.
먼저, 엔터프라이즈에 제공하는 맞춤형 솔루션의 경우 초기에는 그 기업 내부 사용 목적에 특화된, 높은 정확도의 workflow execution (자연어 명령을 이해하고 실행하는) 기능을 위주로 제공하는 것으로 보인다. 이런 회사에서는 동사의 본질적인 고객 페르소나인 지식 노동자들이 집약적으로 모여 있고, 그런 여러 지식 노동자들을 동시에 겨냥한 솔루션을 제공할 수 있다는 장점이 있다. 더불어, 기업 단위로 사용하는 tool의 개수가 한정되어 있기 때문에, 비교적 적은 노력으로 큰 가치를 만들어낼 수 있다. 더 나아가, 동사의 서비스를 도입하는 회사에게 lock-in 효과까지 얻을 수 있고, 장기적인 customer을 확보할 수 있게 되기에, 초기 target으로 설정하기에 매우 적합하다.
이런 enterprise 접근에 대한 시장 자료로는, $79B 규모와 2.73% CAGR를 가진 Productivity Software 글로벌 시장, 그리고 $2.7-4.5B 규모와 17-30% CAGR를 가진 RPA 시장이 참고할 만 하다. 다만 동사의 product을 기존 시장이 정의하는 productivity software이나 RPA tool로는 보기 힘들고, 오히려 동사는 이러한 기존의 기술들이 제공하는 생산성 증대치를 수 배에서 수십 배까지 늘리고 싶어하는 것이 목표이기 때문에, 이런 기존 시장은 동사에게 있어서는 초기 milestone 정도로 보는 것이 합당하다고, 동사가 목표하는 시장 크기는 더욱 클 것이다.
한편, 전체 지식 노동자를 대상으로 하는 horizontal market으로의 진입에서는 조금 더 신중해야 할 것으로 보인다. 아무래도 대중에게 공개할 서비스는 안전성에 엄격해야 하고 또 광범위한 적용 케이스를 커버할 수 있어야 하기 때문이다.
다만, 이 시나리오에서 노리는 market size가 놀랍다.
이런 개인 AI teammate가 노리는 시장의 규모를 먼저 top-down 식으로 어림해보자.
McKinsey의 리포트에 따르면 60%의 지식 노동자가 실제로 하는 과업 중 30%가 현재 존재하는 기술로 자동화 가능하다고 하는데, 동사가 가져올 혁신이 1) 기존 기술 중 컴퓨터 기반으로 작동하는 것은 자동화를 가능하게 하고, 2) 사용자가 모르는 일도 할 수 있게 해준다는 점에서, 전 세계 지식 노동자가 기여하는 시장 크기가 $5T (대략 6500조)인 만큼, 그에 비슷한 스케일의 시장 크기를 노려볼 수 있겠다.

한 리서치 자료에서도 비슷한 시장 규모를 제안한 바 있는데, 지식 노동 자동화 시장의 크기를 전체 지식 노동자의 시장 크기의 약 20%인 $1T (대략 1300조)로 추산하고 있다. 따라서 보수적으로 잡아도 1000조 정도의 놀라운 규모의 TAM이 있다고 볼 수 있겠다. First mover으로서 새로운 시장을 개척하는 동사가 가져올 변화가 얼마나 혁신적일지 보여주는 수치이다.
traction
아직 설립된 지 2년이 채 지나지 않은 태동기에 있지만, AI 업계의 많은 관측들이 동사를 AI 붐의 최전선에 있는 스타트업 중 하나로 꼽곤 한다. 이런 열기를 증명하듯, 동사는 2022년 4월 설립된 후 2년이 채 되지 않은 기간 동안 $415M에 달하는 엄청난 투자 유치 기록을 보여주었다. 자세히 나누어 보면:
Series A (Apr 2022): $65M을 유치하였다. Greylock의 Saam Motamedi, Reid Hoffman, Addition, Root Ventures 등이 주요 투자자이다.
Series B (Mar 2023): $350M을 유치하였다. General Catalyst가 lead, Spark Capital이 co-lead하였다.
특히 AI에 대한 투자 열기가 급격히 사그라들던 2022-2023년에 큰 투자를 받았다는 점이 인상적이다.
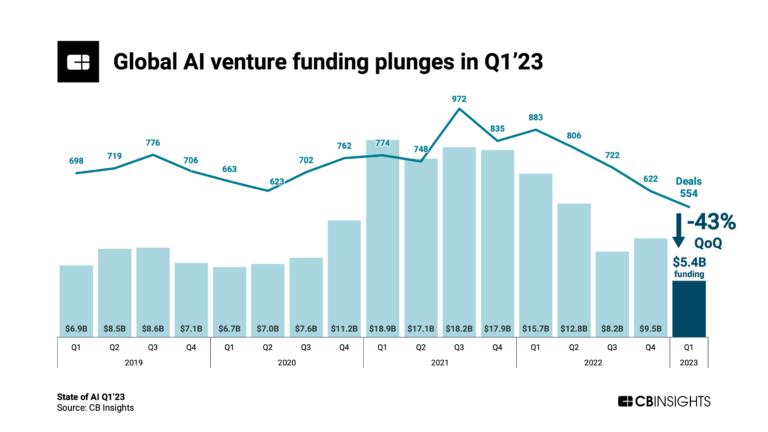
/ 2019~2023 AI의 벤처투자 현황. State of AI Q1'23 Report - CB Insights Research
AI 붐에 따른 GPU 대란으로, 훈련에 필요한 GPU를 원활하게 공급하는 것도 2024년의 AI 기업에게는 중요한 과제이다. 동사는 Oracle Cloud Infrastructure(OCI)과 NVIDIA technology와 파트너십을 맺어, 동사의 목적에 맞게 커스텀 세팅된 NVIDIA A100 Tensor Core GPU를 공급받는다고 밝혔다. 이에 따라 자원 확보를 위한 노력에서 떠나 기술적 발전에만 집중할 수 있는 최적의 환경을 잘 확보했다고 평가된다.
competition
기존의 기업 중 동사와 완전히 같은 목표를 가진 기업은 없지만, 넓게 보면 1) AI agent 개발을 시도하는 스타트업과, 2) 기존 자동화 분야의 기업과의 경쟁이 존재한다.
시작하기 전, 잠시 동사의 고유한 강점을 한 번 정리해보자.
동사는 자체 개발한 모델(in-house model)로 서비스를구동한다.
동사의 모델은 실제로 UI를 이해해서 직접 컴퓨터를 조작한다(actionable).
동사는 단순한 일정 정리 프로그램이 아니라 능동적 조언자인 “AI teammate”를 꿈꾼다.
동사의 모델은 어떤 과정을 통해서 행동을 실행했는지, 백트래킹이 가능하게끔 설계되어 있어 다른 “black-box” 모델들에 비해 의사결정 과정이 투명하다.
AutoGPT
AutoGPT는 2023년 3월에 공개된 오픈 소스 프로젝트(http://github.com/Significant-Gravitas/Auto-GPT)에 기반한 서비스로, ChatGPT의 공개와 함께 한 때 엄청난 traction을 끌었던 프로젝트이다. AutoGPT는 OpenAI의 GPT-3.5와 GPT-4 API를 기반으로 개발되었는데, “작업 X를 처리해줘”라는 명령어를 command line에 넣어주면 ChatGPT에 query를 반복적으로 보내, 어떤 행동을 해야하는지 알려주는 방식으로 작동한다. 쉽게 생각하면 ChatGPT에 “task X를 해결하기 위해 첫 번째로 어떤 일을 해야 해?”라는 질문을 보내고 그 답변을 잘 포장해서 반환한다고 생각하면 된다. 다만 어떤 일을 해야 할지만 알려줄 뿐, 그 일을 대신 해주지는 않는다.

다만, AutoGPT의 현재 투자 과정이나, 추구하는 제품 구조로 보았을 때 동사에 견줄 만한 경쟁자로 보기는 힘들다.
2023년 10월에 $12M funding을 받아 계속 개선 중이지만, 1) GPT 모델 기반이기에 정확도에 한계가 있고, 2) 소스 코드가 상업적 재사용이 가능한 MIT License로 제작되어 있는 점 (=business model이 불분명한 점), 3) fine-tuning을 하지 않고 GPT 모델을 직접 사용하는 점 (=데이터 해자가 없다는 점), 4) AutoGPT 모델이 실제 세상과 상호작용해서 일을 직접 해주는 건 아니라는 점을 감안하면, 동사의 경쟁자가 되기는 힘들 것이다.
Mindy: email-first Chief of staff
Mindy는 이메일 환경에서 작동하는 비서 프로그램으로, Mindy bot에 완수하고 싶은 task를 이메일을 작성해서 보내면, 구글 시스템 내에서 일정 관리, 내용 검색, 질문에 대한 답변 등 사용자의 요청 사항을 수행하는 bot이다.
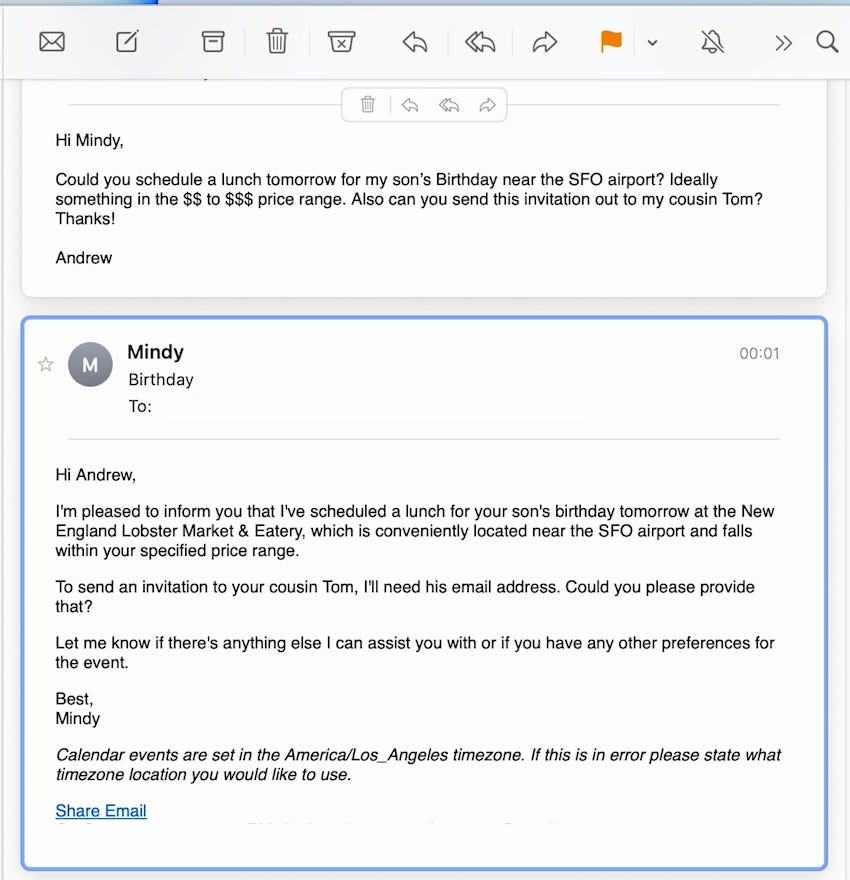
Mindy는 1) 실제로 일정 관리나 검색을 직접 해주고, 2) 자연어로 된 명령을 이해하며, 3) Google 이메일이나 일정 관리 툴밖에 조작할 수 없긴 하지만, “수석비서관”의 역할을 어느 정도 달성하고 있다.
Mindy의 추후 계획에 대해서는 자세히 알 수 없지만, 포지셔닝에 있어서 동사와의 결정적 차이는
1) 이메일 기반으로, Gmail과 연동된 환경에서만 작동하고,
2) 현재로서는 작동 과정이 불투명하고 (어떤 과정으로 task를 수행했는지 알 수 없고),
3) workflow 형태의 접근이 아니므로 반복적인 일을 자동화하는 것은 구조적으로 불가능하다는 점이다.
더불어, 어떤 모델을 사용하는 지는 공개되어 있지 않지만, 3인으로 매우 작은 팀 규모로 보아 in-house model을 쓰고 있지는 않은 듯 해 보여, 정확성이나 추후 성장을 통제하기 어려워 보인다.
이런 점에서, 동사의 product vision이 Mindy의 것보다는 훨씬 강력하지만, 동사가 초기에 어느 시장에 집중하느냐에 따라 Mindy가 어느 정도의 점유율을 가져갈 수 있는 가능성은 있어 보인다. 동사가 노리는 초기 시장은 enterprise customer이지만, Mindy는 개인용 수석 비서관 시장을 초기 시장으로 노리고 있기 때문에, 시장에 초기에 진입해 어느 정도의 점유율을 차지할 수 있다.
따라서, 동사가 Mindy와의 경쟁에서 승리하려면 1) 개인용 product 개발에도 적극적으로 투자해 늦지 않은 시장 진입이 중요할 것이고, 2) 동사 모델의 투명성 (어떤 과정으로 행동했는지를 알 수 있는) + 정확도 + 속도(성능)로 확실한 가치를 어필할 필요가 있다.
Imbue AI
Imbue AI는 설명 가능한 AI를 만드는 것을 궁극적 목표로 하며, 그 목표를 위해 코딩할 수 있는 AI를 개발하는 것에 집중하고 있는 스타트업이다. SQL query를 작성할 수 있는 agent가 코드를 작성할 수 없는 agent보다 더 많은 일을 처리할 수 있을 것이기 때문에, 코드를 작성할 수 있는 AI 개발에 힘쓰고 있다.
이외에는 알려진 점이 많이 없어 구체적으로 분석하기는 힘들지만, 다만 동사와는 달리 Imbue는 아직까지는 순수한 research 기업으로 포지셔닝하고 있다. 개발한 모델을 product로 만들지는 않겠다는 의미이다. 따라서 아직 동사와의 직접적인 경쟁 구도가 드러나지는 않지만, 결국 Imbue와 동사 모두 컴퓨터에서 작동하는 능동적인 agent를 만드는 것이 공통된 목표이므로 장기적인 경쟁자가 될 수밖에 없다.
Imbue 역시 2023년 9월 진행된 Series B round에서 $200M을 투자받으며 $1B가 넘는 valuation을 받았다고 밝힌 만큼, 강력한 팀임은 부정할 수 없다. 따라서, 다시, 기술 개발 속도와 성능이 중요하겠다.
Inflection AI
Inflection AI는 “personal AI”의 시대가 왔음을 강조하며, 감정지능(EQ)을 습득한 인공지능 비서 챗봇의 개발을 꿈꾸는 기업이다. Pi라고 부르는 챗봇 형태의 MVP가 있고, 이를 발전시켜 사용자를 위한, 원하는 정보만 모을 수 있는, 개인 비서 형태의 챗봇을 꿈꾼다. 이런 비전을 인정받아 $1.3B에 가까운 투자를 받아내어, OpenAI, Anthropic에 이어 세 번째로 가장 많은 funding을 받은 가장 핫한 AI 스타트업 중 하나이다.
아직 Inflection AI의 구체적인 목표에 대해서는 밝혀진 바가 많이 없어 구체적인 분석은 힘들지만, 비서 서비스를 제공한다는 점에서 동사와는 비슷하면서도, actionable한 모델을 만들거나 자동화 기능에는 집중하고 있지 않는다는 차이점이 존재한다.
RPA companies
동사의 제품에서 업무의 자동화 및 보조가 핵심적인 가치이기에, 기존의 업무 자동화 시장 (특히 RPA 시장)과 직접 경쟁하게 된다. 대표적으로 UiPath, Appian Corp., Pegasystems가 있고, 현재 시장 점유율 1위인 UiPath의 사례를 집중적으로 살펴보자.
UiPath는 2005년 설립되어 2009년에 전 세계 5000명 고객을 확보하고, 2021년 $1.3B valuation을 인정받으면서 현재 RPA 시장의 market share의 35.8%를 점유하고 있는, 점유율 1위 기업이다. 핵심 서비스로는 앱 개발 과정에서 자동화 workflow를 쉽게 사용할 수 있도록 하는 low-code platform을 제공하는데, 쉽게 생각하면 실행하고 싶은 process의 순서도를 만들 수 있는 UI를 제공하고, 그곳에서 만든 process를 실행할 수 있게 하는 플랫폼이다.
최근 UiPath는 Re:Infer이라는 자연어 처리 스타트업을 인수하는 등 AI 기술 습득에 공격적인 투자를 진행 중이다. 아직은 위의 순서도에 “문서 이해 기능”, “이메일 분류 기능” 등 몇 가지 기술에 적용하는 수준에 그치고, 이 기반 모델도 Google, MS, Abbyy에서 차용해 사용하고 있기에, 동사에 비견할 수준의 인공지능 개발 역량을 갖추고 있지는 않은 듯하다.
UiPath의 AI 도입으로 UiPath의 기존 customer들에게는 엄청난 생산성 향상이 되는 것이 사실이지만, 동사가 약속한 vision에 비하면 아직은 소박하게 보이는 점은 부정하기 힘들다.
두 기업 모두 사용자가 직접 AI 기술을 손쉽게 사용하고 자동화할 수는 있게 하지만, 동사는
1) UiPath의 reactive한 수준을 넘어 모델이 스스로 문제 해결을 돕는 proactive한 모델을 꿈꾸고 있고,
2) 모델을 직접 개발함으로써 이런 기능에 최적화된 모델 개발이 가능하기에
UiPath와는 꿈의 크기가 다르다. 더불어 동사의 제품은 사용자가 구체적인 방법을 몰라도 task를 제시해 주기만 하면 해결해준다는 점에서 동사가 약속한 기술이 실현되기만 한다면, 확실한 기술적 우위를 점할 것으로 보인다.
다만 기존 시장의 강자로서 UiPath의 우위도 몇 가지 있는데, 먼저 기존 customer들이 가지고 있는 충성심(customer stickiness)가 있다. 이미 ARR이 $1B를 돌파했고, 기존 고객들은 UiPath의 플랫폼에 적응하여, 플랫폼에서 RPA 기능 뿐만 아니라 process mining, 자동화 flow를 개발 프로그램과 연동하는 기능, 자동화 과정을 테스트하는 플랫폼 등을 지원하기 때문에 플랫폼으로 확보하고 있는 해자가 있다.
따라서 동사가 이런 전통적인 RPA 기업과의 승부에서 승리하기 위해서는, 다시, 압도적인 성능으로 가치를 어필해야 하고, 둘째로는 자동화와 관련된 핵심 기술 뿐만 아니라 부수적인 추가 기능을 제공할 필요가 있겠다.
valuation
동사가 정확한 수치를 공개한 적은 없지만, Forbes와 ACE Ventures에 따르면 2023년 4월 Series B 단계에서 동사는 $1B 정도의 valuation을 인정받아 유니콘이 되었다. 비슷한 시기(2023 Q1)에 유니콘이 된 다른 기업들로는 Anthropic, Character.AI가 있다.
이런 기업 가치가 합리적인지를 고민해 보기 위해, 먼저 다른 AI 스타트업의 투자 양상, 기업 가치, 그리고 연 매출을 비교해보자.
Adept: $415M funding (Series B, founded 2022) / $1B valuation / $75M revenue
OpenAI: $11.3B funding (Series E, founded 2015) / $80B valuation / $2B revenue
Anthropic: $7.6B funding (Series C, founded 2021) / $18.4B valuation / $850M revenue
Cohere: $440M funding (Series C, founded 2019) / $2.2B valuation / $85M revenue
Character.AI: $150M funding (Series A, founded 2021) / $1B valuation / $16.7M revenue
AI21 Labs: $283M funding (Series C, founded 2017) / $1.4B valuation / $50-60M revenue
Hugging Face: $395M funding (Series D, founded 2016) / $4.5B valuation / ~$50M revenue
AI 스타트업마다 business model이나 사업 구조가 완전히 다르지만, 단순히 연매출과 기업 가치를 비교해 보았을 때 AI 시장 내에서는 funding의 규모나 valuation이 합리적으로 책정된 것으로 보인다.
다만 AI 시장에 거품이 끼어 가치가 전반적으로 고평가된 것 아니냐는 지적이 있을 수 있는데, 실제로 동사를 다른 업무 자동화 기업과 비교해 보면 전혀 그렇지 않다.
대표적인 경쟁 기업인 UiPath는 앱 개발에 필요한 RPA 기술이라는 매우 좁은 버티컬 시장에 집중했음에도 불구하고, $2B에 가까운 금액을 투자 받으며 상장에 성공하여, 현재는 $1B의 연매출을 지속적으로 달성하고 있으며 $11B 정도의 시가총액을 유지하고 있다. 동사의 UiPath에 뒤지지 않는 팀과 기술력, 그리고 목표하는 시장 규모가 UiPath보다 10배에서 100배 이상 크다는 점에 비추어 보았을 때, 동사의 미래 가치를 $1B로 책정하는 것은 그 목표에 비해 저평가되어 있다고 보인다. 다만 아직 동사가 2년차의 극초기 스타트업이고, 아직 가파른 성장의 초입에 있어 실제로 기술이 실현되지 않았다는 점을 감안하여, $1B 정도의 기업가치가 산정된 게 아닌가 싶다.
동사는 이미 충분히 큰 꿈을 가지고 있다. 따라서 강한 팀과 기술력, 그리고 약속한 많은 기능들을 현실로 가져와 스스로의 가능성을 더 선명하게 보여주면서, 그 꿈의 크기가 기업 가치로 연결되게끔 하는 것이 최선의 방향일 것이다.
key ops
아직 초창기의 스타트업이라, 동사의 사업 현황에 대한 분석이나 그 발전 방향에 대해 논하기는 꽤 이른 감이 있다. 따라서 동사의 미래 계획에 대한 분석과, 장기적으로 도움이 될 요소들에 대해 다루도록 하겠다.
positioning
동사의 최대 강점 중 하나는 다각적인 사업 확장이 가능한 강력한 포지셔닝을 구상했다는 점에 있다. 곧,
1) AI 리서치와 상품 출시라는 두 마리 토끼를 모두 잡으면서도,
2) horizontal market을 노리면서도 특정 vertical에 특화된 제품을 제공할 수 있으며,
3) 앞서 다루었듯, business customer과 individual customer를 모두 타겟할 수 있고,
4) software에서 시작해 독자적인 platform 구축까지 노려볼 수 있는,
rich한 기반을 마련했다는 점이다.
각각에 대해 더 자세하게 알아보자.
1. AI research / production
2024년 현재 "AI 기업"이라고 불리는 많은 기업의 본질은 두 가지 중 하나이다: 1) "지능"을 개발하는 리서치 기업, 2) 개발된 지능을 이용해서 인류를 돕는 product에 집중하는 기업.
그리고 신기하게도 이 두 가지를 자연스럽게 동시에 할 수 있는 기업은 손에 꼽는다.
많은 기업들은 마법적 레시피로 만들어진 거대 모델의 API를 살짝 변형해서 쓰는 정도이지, 그 모델의 근본적인 성능을 향상시키지는 못한다. 소위 GPT Wrapper라 불리는 기업들은 ChatGPT의 API를 호출하는 수준이 전부이다.
반대로, 핵심 기술을 개발하는 기업들은 대부분 챗봇 형태의 서비스를 출시하곤 하지만, 아직 초기 단계이다. 실제로 산업에서 사용하기 위해서는 그 버티컬에 맞는 형태로 모델을 그때그때 재가공해야 하기 때문이다. 가령 ChatGPT도 customer service면 customer service, 코드 작성이면 코드 작성 목적에 맞게, 모델을 그대로 사용할 수 없고 그때그때 변형해야 한다.
동사는 이런 두 가지를 모두, 그리고 자연스러운 방법으로 해내려고 하고 있다. 기술 측면에서는 세상에 action을 취할 수 있는 모델을 새로 고안했고, 이 모델에게 세상에 있는 모든 API, 프로그램 UI를 하나하나 가르켜 기계에게 디지털 지능(DQ)을 이식하고자 한다. 그리고 그렇게 함으로써 이 모델 자체가 제품이 된다. 세상에 action을 취할 수 있는 모델은 자연스럽게 우리의 일도 대체할 수 있기에, 완벽한 PMF(product-market fit)이 따라오고, 그러면서 ‘지능 개발’과 ‘제품 제작’이 유기적으로 연결되는 구조를 창조한 것이다.
이런 구조적 혁신이 동사의 사업 확장의 안정성으로 연결될 것이다. 모델 개발과 제품 개발이 같은 곳에서 일어나 효율적이라는 장점도 있지만, 상품 개발이 DQ 확보를 위한 cash flow를 벌어다준다는 면에서 생각해보면 재정적으로도 큰 도움이 된다. 이렇게 모델에 대한 투자는 다시 성능 향상으로 이어져 양성 피드백 사이클을 만든다.
이와 더불어, 동사가 text나 image를 이해하는 모델을 만드는 것이 아니라, 다른 기업들이 전혀 연구하고 있지 않는, "컴퓨터 UI"에 대한 정보를 이해하는 기계를 만들려 하는 점 자체가 또다른 기회가 될 수 있다. 예를 들어, 흥미롭게도, 이런 기술 개발이 어쩌면 AR/MR(augmented/mixed reality) 산업과의 파트너십으로 연결될 수 있지 않을까 생각되는데, 가령 AR 기계에서 실제 세상에 존재하는 컴퓨터의 UI를 인식하면, 그 컴퓨터에 연결해서 AR 기계에서 원격으로 동사의 제품을 이용해서 컴퓨터를 조종하는 멋진 기술도 구현할 수 있지 않을까 싶다.
2. market
동사가 차지할 수 있는 market도 풍요롭다. 현재로서는 개인용 productivity tool로 크게 enterprise와 individual용 horizontal solution가 주된 대상이지만, 조금만 관점을 바꾸면 정말 다양한 버티컬 시장의 진입도 가능할 것으로 보인다.
동사가 enterprise 솔루션에 접근하는 방식에서 그 힌트를 얻을 수 있다.
동사가 현재 집중하는 기업 솔루션의 기술적 본질은 fine-tuning이다. 각각의 enterprise에서 사용하는 software이나 주요 workflow에 특화하여, 실제 사용에 가까운 예시들을 많이 생성하여 모델을 추가적으로 훈련시키면서 enterprise 내부에서의 사용 정확도를 엄청나게 올려주는 식이다.
이것의 반대쪽 극단은 개인용 product로, 모든 software과 workflow에서 잘 작동하는 일반적인 서비스를 구축하는 것이다. 그리고 이 사이에 있는 것이 바로 특정 vertical 시장으로의 진입이라고 볼 수 있다.
가령 금융 시장을 예로 들어보면, business research 등의 목적에 특화된 application을 제공할 수 있다. 시장 분석을 업으로 삼는 지식 노동자들에게 자료 조사를 위한 자동화 툴을 제공한다거나, 관련된 뉴스 주제들을 fetch하는 기능 등을 자동화해서 엄청난 생산성 향상을 이루어낼 수 있다.
아니면 정말 특수한 소프트웨어를 겨냥할 수도 있다. 예를 들어, Mindy가 Gmail, Google calandar, Google 검색을 활용하는 것처럼, 동사도 이런 프로그램에 특화된 솔루션을, fine-tuning을 통해 엄청난 정확도로 제공할 수만 있다면 시장 진입이 가능해진다.
이런 예시에서 보이듯, 동사는 컴퓨터 상에 존재하는 모든 소프트웨어, 웹페이지 등을 레버리지로 사용하는 셈이다. UI를 잘 이해하는 원천 기술이 있기 때문에, 큰 노력 없이 기계가 한 소프트웨어의 사용 방법을 정복할 수 있게 한다. 한편 지식 노동자들은 몇 가지 소프트웨어를 다루는 법을 몇 년에 걸쳐 배우고, 그 툴들만 반복하면서 사용하므로, 동사의 버티컬 시장 진입이 특히 쉬워진다.
이렇게 버티컬 시장에 진입할 때의 관건은, 아무래도 동사가 얼마나 경쟁력 있는 가치 어필을 할 수 있는지이다. 가령 시장 리서치에 사용되는 자료는 정확해야 하고, 트레이딩에 사용되는 자료는 빨라야 한다는 성질을 만족시켜야 한다는 것이다. 이는 곧 동사가 진출할 수 있는 시장을 얼마나 잘 캐치하는지, 그리고 그 버티컬에 특화된 혁신을 이뤄낼 수 있는지에 달려 있다.
동사가 현재 enterprise에 제공하는 솔루션의 정확도가 95%를 넘는다고 밝힌 만큼 전망은 긍정적이다. 동사가 진출할 수 있는 시장이 무궁무진하기 때문에, 이런 사업 확장에 적극적으로 투자하고 기술력 차이를 확보하는 것이 중요할 것이다.
3. software to platform
그러면 동사는 이런 product를 어떻게 호스팅하고, 더 가치 있는 user experience를 만들 수 있을까?
우선 동사가 제안하는 대로, SaaS 형태로의 가치 제안이 가능하다.
동사의 MVP에서 보이듯, 데스크탑에 background overlay로 작동하면서, 모니터에 대한 제어권을 받아 query를 직접 실행시켜 사용자에게 도움을 줄 수 있다. 소비자는 이런 actionable한 일반지능을 활용해서 개인의 업무 처리 능력을 향상시킨다. 심지어 개별 소프트웨어를 작동시키는 법을 몰라도, 하고 싶은 일을 high-level로 설명할 수만 있으면 스스로 할 수 없는 일도 단계단계 해결해주는, 자동화 툴의 혁신이 가능하다.
이렇게 고객들을 확보하고 나서는, 그 다음 단계로 전용 플랫폼을 구축해 사용자 간의 교류를 통해 새로운 가치를 창출해볼 수 있을 것이다. 예를 들어 커스텀으로 만든 workflow를 공유할 수 있게 하는 플랫폼을 만드는 일을 상상해 볼 수 있다. 다른 사람이 올린 workflow를 올리고, 다운받아 자신의 컴퓨터에서 실행해볼 수 있는 시스템을 구축해서, 생산성 향상에 초점이 맞추어진 커뮤니티를 형성하는 것이다. 사용자가 해결하고 싶은 문제를 구체적으로 기술하는 단계를 넘어서서, 가령 "컴퓨터 IP 주소 세팅 법", “코딩 환경 구축”, “환경 설정 세팅”과 같이 전문적인 지식이 있어야만 문제를 정확하게 기술할 수 있던 기술적인 문제들도 해결 가능하게 된다. 또는 기업 내에서, 한 사람만 알고 있는 지식을 다른 사람들에게 workflow의 형태로 손쉽게 공유할 수 있게 되면서, 개인의 생산성 향상에서 조직의 생산성 향상으로 이동해서 새로운 가치를 어필할 수 있겠다.
한 가지 덧붙이자면, 단순한 공유 기능보다도 workflow를 사고 팔수 있게 하는 플랫폼을 구축해서, 사용자와 판매자들을 유인하는 것도 가능해 보인다. 가령 GPT Store처럼 개인이 모델을 fine-tuning할 수 있게 허용해서, fine-tuning된 모델을 사고팔 수 있게 할 수도 있고, 아니면 스스로 만든 workflow (가령 “Word 설치 workflow” 같은 것들)도 사고팔며 소비자들을 플랫폼으로 끌어들일 수 있겠다.
아직은 시작 단계이지만, 이렇게 플랫폼으로의 확장까지 가능한, 무궁무진한 확장 가능성을 지니고 있다.
domain moat
production을 목표로 하는 AI 기업이 세울 수 있는 가장 흔한 해자는 데이터에 있다. 새로운 모델을 개발할 수 있는 역량을 가진 기업은 흔치 않으므로, 특정 버티컬의, 공개되지 않은 양질의 데이터를 확보하고, 그런 데이터로 모델을 훈련시켜 모델의 성능에서 차별화하는 전략을 대표적으로 사용하는 것이다.
동사는 이런 전통적인 전략과는 다른 길을 선택하였다. 동사는 다른 팀들과는 다르게 이런 기본적인 모델을 처음부터(from scratch) 개발할 수 있는 능력이 있기에, 더 나은 접근을 시도할 수 있었다. 거대 LLM 위주가 장악하는 시장에서, LLM 열풍 다음에 올 파도가 agent 기반의 AI가 될 것이라는 점을 빠르게 캐치하고, agent 기반의 AI 모델이라는 새로운 모델을 개발하기로 결심한 것이다.
실제로 동사의 분석은 정확했다. 2024년의 화두는 Agentic AI가 될 것이라고 전망하는 의견이 대거 나오고 있고, 동사가 빠른 시작으로 이러한 움직임의 선두에 있게 되었다.
이런 측면에서 동사의 해자는 동사의 모델, 더 근본적으로는 domain에 있다. 여기서 도메인이라 함은 동사의 AI 모델이 기존의 text, image로 된 대상을 다루는 것이 아니라 “action”이라는 새로운 도메인을 활용한다는 느낌으로 생각하면 좋겠다. 모델 자체의 종류를 바꾸어 버리면서 AI agent에 대한 지식이 없는 기업은 따라올 수 없도록, 새로운 시장을 열고 엄청난 해자를 설립한 것이다.
다만 이런 domain 해자가 후발 주자들을 긴 시간 동안 막아줄 수 있는지는 숙고해볼 필요가 있다. 이때 크게 관건이 되는 요소는 1) 모델 구조가 어느 정도는 공개되어 있다는 점과 2) AI 산업의 본질적 모호성이 있겠다.
첫째로, 동사가 개발한 모델의 원천은 Transformer 모델이다. 즉, text 기반의 LLM 모델들, 그리고 image를 다루는 모델들과 기본 모델의 뼈대는 같다. 어떻게 보면 동사 모델의 일부는 공개되어 있는 셈이다.
다만 동사의 기술력은 이런 기본 transformer 골격을 어떻게 활용해서 실제 action을 취할 수 있는 모델을 개발한 것이다. 어떤 전문가들은 이런 transformer 구조를 변형해서 action을 취하는 모델을 만든 것이 거의 불가능해 보인다고 평가할 만큼 우선은 기술 격차를 어느 정도 확보했지만, 모델의 기본 구조가 어느 정도 알려져 있는 만큼 완전히 안심할 수는 없다.
둘째로는 AI 산업의 본질적인 모호함이다. 본질적으로, 높은 수준의 지능은 무엇이든 할 수 있기에, domain이 큰 문제가 되지 않을 것이라고 볼 수 있다는 것이다.
가령 엄청나게 똑똑한 GPT가 나오면, GPT가 동사의 일부 기능은 손쉽게 대체할 수도 있다. 예를 들어, “Excel에서 이 금융 데이터를 가지고, 평균 성장률을 분석해서, 이메일로 보내고 싶어.” 같은 명령을 처리하려면, Excel의 현재 데이터를 복사한 뒤, 이런 식의 질문을 하는 것이다: “내가 Excel에서 이 금융 데이터를 가지고, 평균 성장률을 분석해서, 이메일로 보내고 싶은데, 어떤 순서로 마우스와 키보드를 눌러야 할까?” 충분히 똑똑한 GPT가 이것에 대한 답변을 주면, 그 답변을 받아 실행시킬 수 있는 간단한 프로그램을 이어 붙여 동사의 workflow execution 기능을 순식간에 모방할 수 있다.
다만, 이런 방식으로 AI teammate를 만드는 동사보다 월등한 제품을 출시하려면 적어도 10배 정도의 압도적 차이를 보이는 지능을 확보해야 할 것이고, 또한 workflow의 제작 및 실행을 넘어서, 능동적인 AI teammate를 확보하려면 어느 정도 action이라는 domain에 관련된 정교한 작업이 필요하기 때문에, 동사에게 아직은 실존적인 문제가 되지는 못 한다. 다만, 역시 속도의 문제이다. AI Agent 뿐만 아니라 다른 foundation model을 개발하는 기업들의 속도를 계속 따라가야 한다. 그러면서, 이런 domain 해자가 절대적이지 않을 수 있다는 점은 명심해야 할 것이다.
Team
동사의 team은 동사가 가진 최고의 자산이다. 아무래도 foundation model 개발 능력으로 승부를 봐야 하는 상황이고, full-stack으로 서비스 개발을 할 수 있어야 하며, 한 모델의 개발에만 몇십-몇백명씩 투입하는 전통 강자들 사이에서 틈을 벌려야 하기 때문에, 이러한 기술 경쟁에서 승리하기 위해 최고의 팀이 필요할 수밖에 없다.
초기의 거대 AI 발전 과정에서, foundation model의 개발에 필요한 지식은 학계가 아니라, 엄청난 양의 GPU를 소유한 극소수의 기업에서만 습득할 수 있어서, 현재 industry 최고의 전문가들은 Google과 OpenAI의 리서치 그룹에서 파생되어 나왔고, 다음 “family tree”처럼 모두 연결되어 있다.
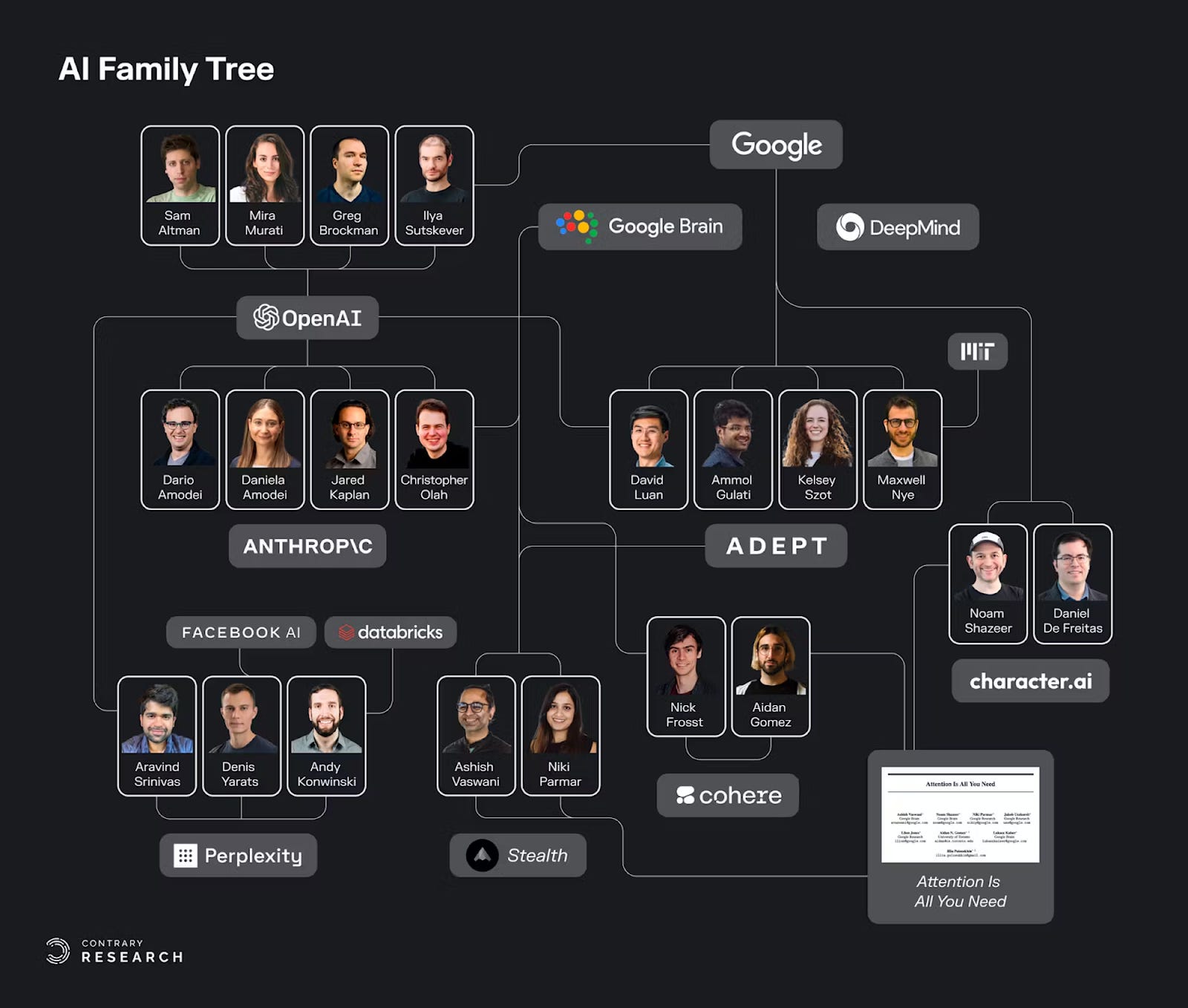
이런 점에서, 동사의 팀 구성은 강력하다. 대부분의 초기 멤버가 이 리서치 그룹에서 핵심 프로젝트를 이끌던 이들이기 때문이다.
Today, we’re a growing team of nine leaders in AI: Kelsey Schroeder, who led product for Google’s giant model production infra; Erich Elsen, a GPU computing pioneer who most recently co-led DeepMind’s giant model scaling effort; Augustus Odena and Max Nye, who built Google’s code generation model; Anmol Gulati, who built Google’s production speech recognition model; and Fred Bertsch, our group’s expert in data and collaborative AI systems at Google. We believe engineering, research, product, and design are equally important in building this next phase of AI.
/ adept.ai, “Introducing Adept”
특히 Max Nye와 Kelsey Szot은 2024년 Forbes 30 under 30에 선정되기도 할 만큼, 슈퍼스타로 구성된 초기 팀을 만들어 내었고, 이후에도 Tri Dao 등 유망한 학자들과 협업하거나 위의 리서치 기업들에서 지속적으로 인재를 끌여들이고 있는 것으로 보인다.
다만 우려되는 뉴스가 하나 있는데, 초기 co-founder 중 두 명 (Ashish Vaswani, Niki Parmar)이 1년 후 퇴사해서 아직은 공개되지 않은, 새로운 AI 기업을 꾸려가고 있다는 소식이다. 두 co-founder의 퇴사 이유는 밝혀지지 않았고, 인터뷰에서도 잘 언급되지 않고 있다.
강한 팀일수록 강한 구심점과 리더십이 필요한 법인데, 그러한 점에서 초기 co-founder의 이탈은 아쉬운 면이 있다. 하지만 지나간 일은 어쩔 수 없는 법, 동사로서는 내부 문화를 잘 정리하고 결속을 다지는 방법 뿐이고, 이제는 76명이 넘는 팀으로 성장한 바, 지속적으로 좋은 인재를 유치해야 한다.
key risks
Competition
좀 상투적인 지적이지만, 경쟁에서 밀려나는 것이 동사의 현실적인 최대 리스크이다. 특히 AI 시장은 아무래도 빠르게 변하고 있고, 기술에 심하게 의존하기 때문에 어느 정도의 승자 독식 구조가 생길 수밖에 없기에, 동사는 최고가 되기 위한 기술 발전을 빠른 시간 내에 이뤄내야 생존할 수 있을 것이다.
이전에 살펴본 경쟁사 중에서 현재 동사에게 생존적 위협이 되는 것들은 없으나, 오히려 아이러니하게도 동사의 최대 경쟁자는 아직 stealth mode에 있는 회사일 가능성이 높다. 특히 그 중에서도 공개적인 funding round를 거칠 필요가 없는, OpenAI, Anthropic, Google, Facebook 등 “AI 쩐주”들의 stealth project들을 주의해야 한다.
실제로 OpenAI에서 현재 Agentic AI 모델을 적극적으로 개발 중이라는 보도가 나오고있는 만큼, 후발 주자들이 시장에 달려들기 시작한다면 시장 내 동사의 입지가 필연적으로 흔들릴 것이다.
이런 경우에 동사가 강조할 수 있는 전략은 한정적이다:
1) early start 효과의 극대화: 빠르게, 강력한 기술을 개발한다.
2) lock-in 효과: 제품을 최대한 빠르게 공개해서 lock-in 효과를 노린다.
3) 안전성에 대한expertise를 살리기: AI의 성능에서는 OpenAI와 같은 기업이 우위를 점할 수 있어도, “안전한 AI”에 대한 전문성을 살려 측면 공략을 시도할 수 있다.
궁극적으로는 제품 출시 시기와 성능이 시장의 승자를 결정할 것이고, 경쟁에서 패배하더라도 다른 부수적 요인들을 최대한 끌어모아 어떻게든 생존할 수는 있겠지만, 어찌 되었든 승자 독식이 심한 시장 특성을 고려할 때, 유효한 경쟁자가 없는 현재 상태에 안주해서는 안 될 것으로 보인다. 즉, 다시, 속도가 생명이다.
Safety, regulation
AI 시스템에 대한 법적 제약은 아직 활발히 논의되지 않고 있지만, AI 기술이 가져올 생산성 혁명에 의한 파급력을 생각해볼 때, 안전한 AI 사용에 대한 강력한 규제가 몇 년 이내에 도입될 가능성이 높다. 아직은 기술의 초창기이기에 제도가 완벽하게 갖춰지지는 않았지만, 동사가 주의해야 할 몇 가지의 법적 리스크가 있다.
1) private data
2022년 말, New York Times가 OpenAI와 Microsoft를 대상으로 저작권 침해 소송을 제기하였다. 소송의 골자는 1) OpenAI가 ChatGPT를 훈련시키는 과정에서 NYT의 기사 자료를 이용함에 따른 저작권 침해, 2) ChatGPT가 대답을 생성할 때 NYT 기사를 오인용하면서 생긴 NYT의 브랜드 가치 손상에 있다. 특히 놀라운 점은 적절한 prompt를 주었을 때 ChatGPT가 NYT의 특정 기사의 내용을 “거의 똑같이(near-verbatim)” 대답으로 반환하였다는 점이다. NYT의 소송 이후 많은 예술가들이 OpenAI에 비슷한 내용의 소송을 계속 걸어 온다고 하는데, 이런 소송이 실제 OpenAI의 패소로 이어질 경우 OpenAI의 서비스나 재정 상황에 큰 영향을 줄 것임은 명백하다.
이런 소송의 결과가 어떻게 되던지, AI 산업에 있어서 시중에 있는 많은 양의 데이터가 무조건 장점만은 아님을 명확히 보여준다. 데이터의 양이 많고 질이 좋을수록, 그 데이터를 생산하는 주체들에 대한 적절한 보상이 필요할 수 있기에, 어느 정도의 리스크가 따라온다.
동사가 모델 훈련 과정에 사용하는 데이터에 관해서는 알려진 바가 적지만, 동사의 비전이 모든 프로그램을 사용할 수 있는 AI을 구축하는 것이므로, 이미 널리 사용되는 프로그램에 관한 정보를 사용할 가능성이 높다. 가령 어떤 프로그램을 포함하는 workflow를 지원하기 위해서는, 그 프로그램의 documentation이나 실제 사용 영상 등을 훈련 데이터로 이용할 가능성이 높은데, 이런 데이터를 직접 만들지 않는 이상 그 프로그램을 이용한 영리적 사용에 법적 제동이 걸릴 수 있다는 문제가 있다.
이런 측면에서 엔터프라이즈용 솔루션에 집중하는 동사의 현재 포지셔닝은 매우 적절하다고 판단된다. 엔터프라이즈 내부에서 사용되는 소프트웨어에 대한 workflow 자동화 툴를 개발하는 것은 사적 데이터 사용에 대한 논란의 여지가 거의 없기 때문이다. 다만 추후 대중에게 공개할 만한 “teammate” 서비스는 이런 법적인 문제를 피해야 하므로, 세 방법 중 하나를 선택해야 한다:
특정 프로그램에 대한 특이적인 데이터를 사용하지 않고 훈련하는 기술을 개발한다. 가령 Word 프로그램을 지원한다면, Word 사용법이나 사용 영상과 같은 사용자 정보에 의존하는 것이 아닌, 실제로 인간이 Word 프로그램을 처음 사용하는 것처럼 순수한 Computer Vision 기술과 언어 이해 능력을 바탕으로 작동하는 프로그램을 설계한다.
목적에 맞는 데이터 생산에 집중한다.
위의 방법이 좋은 성능을 가져다주지 않는 프로그램들에 대하여, 프로그램 제공사와 파트너십을 맺거나 법적 모호함을 해소하는 새로운 방식으로 프로그램을 설계한다.
더불어, 동사가 “훈련 데이터가 노출되지 않도록” 안전한 모델을 설계하는 것도 중요하겠다.
2) data collection
동사의 중추가 되는 action 기반의 모델은 업계와 학계에서 모두 깊이 논의되지 않은 새로운 것이기에, 동사가 어떠한 방법으로 모델을 훈련시키는지에 관해서는 단정짓기 힘들다. 다만 ML 모델의 일반적인 개발 양상에 비추어 보았을 때, 기본적인 모델의 뼈대를 개발한 후에는 scaling law를 이용하여 성능 향상을 노릴 가능성이 높다. 통상적으로 “한 단계”의 scaling을 위해서는 10배 이상의 데이터가 필요하다. 가령 GPT-2가 40GB의 데이터를 이용해서 개발되었다면, GPT-3은 570GB의 데이터를 사용하여 훈련한 것이 대표적인 예시이다. 이 부분에서 동사의 최대 강점으로도 보았던, domain의 차이가 오히려 발목을 잡을 수 있다.
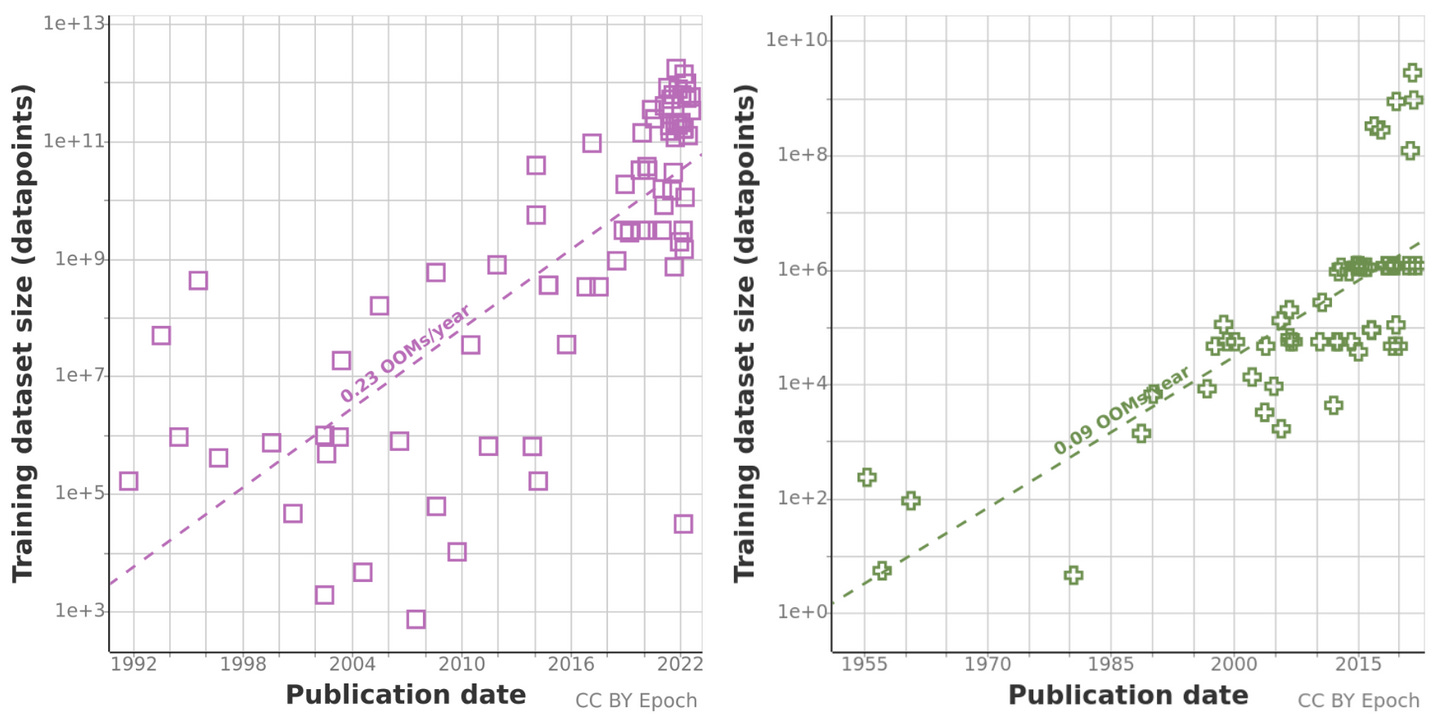
/ source: Trends in Training Dataset Sizes – Epoch (epochai.org)
text나 image 중심의 거대 모델이 주류가 된 핵심적인 이유는 큰 노력 없이 기하급수적인 양의 데이터를 확보하기 쉽기 때문이다. 당장 인터넷 웹페이지만 보아도 text와 image를 수없이 찾을 수 있지만, 동사처럼 “UI를 이해해서 작업을 수행하는” 데이터를 찾아보기는 힘들다.
따라서 동사는 통상적인 scaling law를 레버리지하기 위해서 데이터를 수집하는 특별한 방법을 모색하거나, 적은 데이터로 성능을 효과적으로 향상시킬 수 있는 새로운 방법을 모색해야 하겠다.
3) Product: 행동에 대한 책임
동사가 실제로 인간의 도움 없이 구동되는 자동화 시스템의 도입을 꿈꾼다면, 동사 제품의 잘못된 행동이 가져오는 피해 구제에 대한 법적 프레임워크가 중요한 변수이다. 이 방면에서는 자율주행 자동차의 도입과 관련된 법적 리스크과 비슷하게, AI agent가 세상에 직접 행동하는 엄청난 강점을 가져오지만, 반면 0.001%의 확률로 일어나는 오류에 따른 파장이 엄청나게 커질 수도 있다.
가령 사용자가 악의적인 의도로 “이 사이트를 해킹할 방법을 찾아줘.” 등의 질문을 해서 실제로 해킹을 해 잘못된결과로 이어질 수도 있고, 사용자는 순수한 목적으로 프로그램을 사용하였지만 동사의 제품이 workflow를 실행시키는 과정에서 database를 날려버린다거나 할 수 있으므로, 동사의 product가 안전하게 작동하지 않으면 큰 법적 리스크를 만들 수 있다.
While Adept is pushing AI frontiers, their approach is decidedly human-centered. This is not a story of replacing knowledge workers, but rather seeking to empower them in the driver’s seat, with a machine riding alongside, to discover new solutions, enable better decision-making, and give us more time for the parts of work we love and yet somehow deprioritize.
/ General Catalyst
동사도 이런 문제를 인지하고 있는지, ”사람을 대체하는 제품이 아니라, 사람을 보조하는 제품을 만든다”고 하고 있지만, 이 정도로는 부족하다. 어쨌든 모델이 실제 인터넷에 제한 없이 접근할 수 있기에, 사람이 보조한다고 한들 예상치 못한 일이 일어날 수 있기 때문이다.
아무리 기술적으로 진보하여도 이런 리스크를 완전히 해결할 수는 없겠지만, 최소한 입법 기관과 다른 관련 기관과의 담론에 적극적으로 참여하는 것이 중요할 것으로 보인다.
Ending thoughts
Adept는 여러모로 우리를 설레게 할 기업이다. 영화에서만 보던, 아이언맨의 자비스 같은 존재를 모든 지식 노동자에게 안겨주기를 약속했고, 그 시작으로 이미 기존에는 보지 못했던 기술들을 성큼성큼 보여주며 새로운 생산성 혁명의 선두에서 뛰어가고 있다.
다만, 계속 강조했듯, 아직 갈 길은 멀고, 많은 것을 보여줘야 한다. 보이지 않는 경쟁자들이 따라오고 있고, 모호한 법적 문제는 계속 나타날 것이며, 기술적 우위는 계속 위협받을 것이다.
하지만 처음은 언제나 어려운 법. 슈퍼스타들로 이루어진 강력한 팀과, 원천 기술에 대한 집착이 그들을 성공적으로 이끌어가기를 바라며, 동사에 대한 분석을 끝맺는다.